【神经网络】深度学习的数学基础
昨天刚和老师讨论完,本人的线代和概率还停留在只会做题的水平(好吧题也快不会做了),老师建议我多找找外国的公开课啥的,今天正好软工课的视频讲到了有关知识,所以来写个总结。
机器学习(深度学习)中的数学模型
主流技术主要是线性代数、概率论(包含信息论)、最优化(微积分)(BP以及神经网络求解的最后其实都是最优化问题)。(班主任让我多学线代和概率诚不欺我)
神经网络在学什么
这部分在 Hinton 的课程里已经讲了很多了,总的来说就是找到一个能够符合所有样本的权重值。而在求解的过程中,需要用到线性代数,也就是每次与矩阵相乘都可以看作是空间和维度的扭转变换。
矩阵线性变换
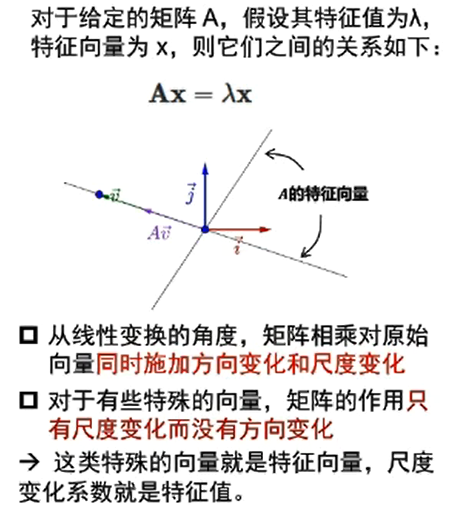
$\lambda x$ 的结果,由于 $\lambda$ 是数字,因此不会对 x 产生方向变化,只会产生尺度变化,这就意味着当矩阵 A 与 x 相乘后,只产生了尺度变化,此时 x 为 A 的特征向量,尺度变化系数就是特征值。
看看下面这个图,更好理解。第一个图是 v 为 A 的特征向量时的结果,可以看到只产生了尺度变化;第二个图不是,因此同时产生了尺度变换和方向变换。
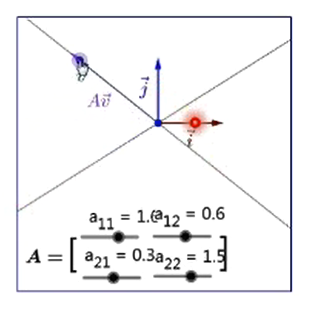
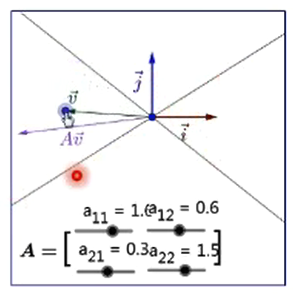
下图是一个向量 v ,和矩阵 A 的一次、二次等等相乘得到的图像,可以看出,矩阵相乘越多次,结果越接近矩阵最大特征值对应的特征向量,也就是说每次向量 v 与矩阵 A 相乘,都会更加接近矩阵 A 最大特征值对应的特征向量。
秩
定义:
- 线性方程组的角度:度量矩阵行列之间的相关性。如果矩阵的各行或列是线性无关的,矩阵就是满秩的,也就是秩等于行数。
数据点分布的角度:表示数据需要的最小的基的数量。
数据分布模式越容易被捕捉,即需要的基越少,秩就越小。(我理解的是,越有规律的样本集,数据分布模式越容易被捕捉)

比如说上面这张图,显然左边的秩比较小。
数据冗余度越大(数据越集中),需要的基越少,秩越小。
若矩阵表达的是结构化信息,如图像、用户-物品表等,各行之间存在一定相关性,一般是低秩的。(这里稍稍理解上有点问题)
先把他给的例子截个图

从左到右,左边的秩最小,右边最大。
机器学习:数据降维
知识盲区。。。先记下来。
图像压缩的一个例子:

机器学习:低秩近似

海,先记下来。
机器学习三要素:模型、策略、算法
概率/函数形式的统一
模型
指数族:可以看作对某些概率分布的一个标准化形式(????)


广义线性模型:逻辑回归等都属于此模型
二者之间有一对一的关系。比如指数族属于高斯分布,那么对应的决策函数一定是一个线性回归。
策略
给出目标函数后,从假设空间中学习/选择最优模型的准则。
极大似然估计/最大后验。
经验风险最小化/结构风险最小化。
算法
这里是不是要讲一下Delta Rule了(猜测)
比起启发式优化算法,梯度下降的方法在面对大量数据的时候效率更高;启发式优化算法更擅长处理局部最优解问题,而很多的问题是没有局部最优解(最小值)的,而是会有很多鞍点。
举个栗子

蒙圈了,先记下来。
“最优”的策略设计
最适合的模型:追求泛化能力的模型
之前只是简单了解了泛化能力的概念,这里是定量的描述:

x y 代表输入和实际值。
更多情况下我们计算的是训练误差:

最终的目的:获得小的泛化误差
- 训练误差要小
- 训练误差与泛化误差足够接近(不懂为啥)
- 计算学习理论:衡量训练误差与泛化误差的差异(知识盲区)
无免费午餐定理
简单来说就是,一个模型不可能适用于所有的情况。在脱离实际意义情况下,空泛的谈论哪种算法好毫无意义,要谈论算法优劣必须针对具体问题。
奥卡姆剃刀原理
“简单有效原理” “如无必要,勿增实体”
这里提到了一个“欠拟合”和“过拟合”的概念。欠拟合就是说,训练集的一般性质尚未被学习好,比如将绿色叶子作为训练集,欠拟合情况下它会把一棵树也看作是叶子;过拟合是指,训练误差小,测试误差大,例如恰好训练集中的叶子都是尖齿的,那么在过拟合情况下,会认为圆边缘的叶子不是叶子。
解决方案:
欠拟合:提高模型复杂度
- 决策树:拓展分支
- 神经网络:增加训练轮数
过拟合:降低模型复杂度
- 优化目标加正则项
- 决策树剪枝
- 神经网络:early stop、dropout
数据增广:训练集越大,越不容易过拟合
- 计算机视觉:图像旋转、缩放、剪切
- 自然语言处理:同义词替换
- 语音识别:添加随机噪声
损失函数
讲到类似 Delta Rule 了

有关交叉熵完全没懂,后续补坑。
Beyond 深度学习
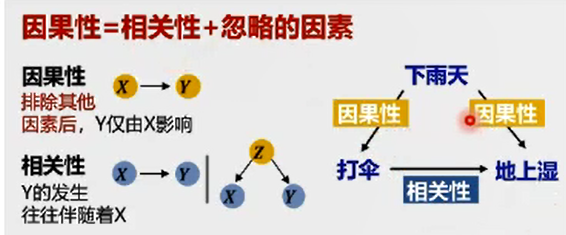
因果推断
Yule-Simpson 悖论
相关性不可靠,很容易被其他因素所干扰。
举个例子

因果性 = 相关性 + 忽略的因素