
绪论
卷积神经网络的应用
计算机视觉(人脸识别、图像生成)自动驾驶等等
传统神经网络 vs 卷积神经网络
损失函数:衡量吻合度(结果准确度)
传统神经网络的学习过程举例:
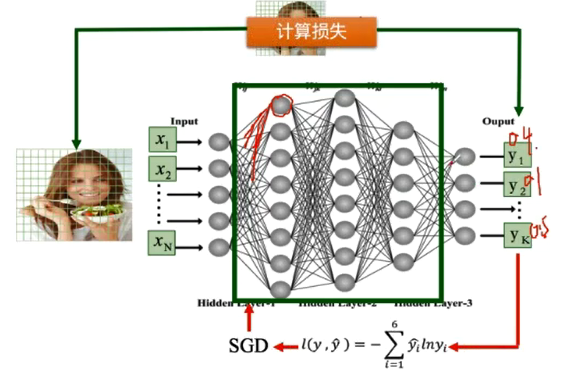
经过一次学习后,计算交叉熵(误差),根据 SGD随机梯度下降法进行学习纠正。
传统神经网络(全连接)面对参数较多的情况时,容易造成过拟合的现象。因此传统的神经网络应用到计算机视觉上时效率比较低。
这里假设输入的图像是300x300大小的。
传统神经网络:假设我们用一个有128个单元的全连接层,则我们需要300x300x128=11520000个参数(不考虑偏置)。
卷积神经网络:假设我们采用5x5x3的filter,对于不同的区域,我们都共享同一个filter,因此就共享这同一组参数,一个filter有75个参数,假设我们使用10个filter,则需要750个参数(不考虑偏置)。
基本组成结构
一个典型的卷积网络是由卷积层、池化层、全连接层交叉堆叠而成。
卷积
概念:是对两个实变(以实数为自变量)函数的一种数学操作;滤波器/卷积核。
例如,在图像处理中,图像以二维矩阵形式输入神经网络,因此我们需要二维卷积。
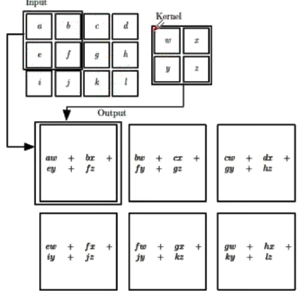
给定一个图像 $X\in R^{M\times N}$ 和滤波器 $W\in R^{m\times n}$ ,计算 $y = Wx+b$ 。
卷积核中每个值为权重;每次卷积核进行计算时对应输入矩阵中的一块区域称为感受野;卷积后生成的结果称为特征图;深度(channel)指一层上卷积核个数。
padding:零填充
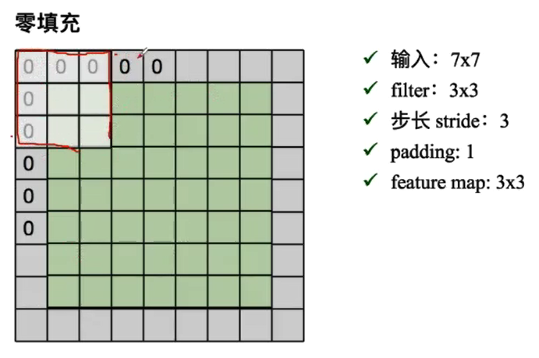
输出的特征图大小计算:
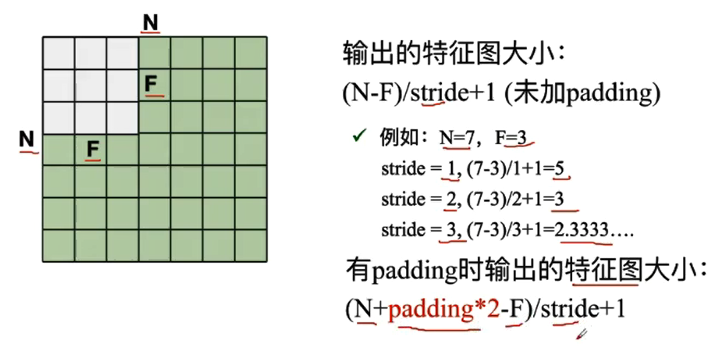
最后我的理解是,卷积的过程,就是从上一层数据中提取重要的特征数据送到下一层,可以用来减少参数值。
池化
保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。一般处于卷积层与卷积层之间,全连接层与全连接层之间。
最大值池化(分类识别时常用)
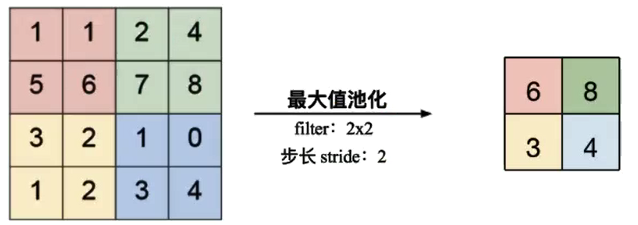
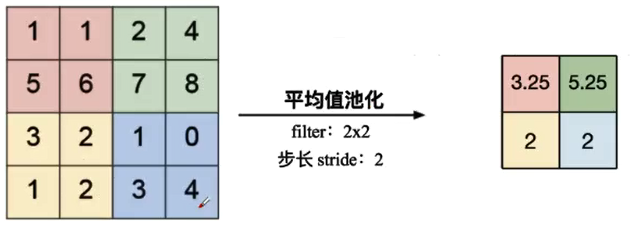
平均池化
全连接
- 两层之间所有神经元都有权重相连
- 通常全连接层在卷积神经网络尾部
- 全连接层通常参数量最大
卷积神经网络典型结构
AlexNet
特点

关于RELU激活函数的特点之前总结过了,它能解决正区间内梯度消失的问题,且计算速度更快,收敛速度快。
Dropout 随机失活:训练时随机关闭部分神经元,测试时整合所有神经元,来防止过拟合。
数据增强:
- 平移、翻转、对称
- 随机crop。训练时,对于256 256的图片进行随机crop到224 224。
- 水平翻转,相当于将样本倍增
- 改变RGB通道强度
- 对RGB空间做一个高斯扰动(体现为改变照片中猫咪的颜色)
结构
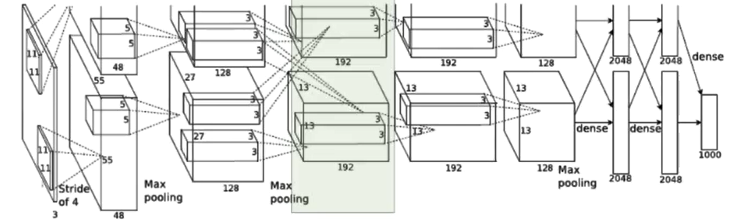
第一到五层:卷积—ReLU—池化
第六、七层:全连接—RELU—DropOut
第八层:全连接—SoftMax
ZFNet
网络结构与AlexNet相同,只是将步长和感受野减小,以求得更加精确的结果。
VGG 卷积神经网络典型结构
网络更深
GoogleNet

可以通过多卷积核增加特征多样性。
ResNet
残差学习网络,深度达到了152层。
占坑,想后面详细了解下。
