什么是强化学习
是让计算机从不会到会,不断尝试,从错误中学习达到目标的方法,更新自己的行为准则,最终达到学习的目的。
强化学习的分数导向性
理解为在电脑中有一个老师在为行为打分,有一类行为会被打高分,有一类会被打低分,类似于在监督学习中的正确标签,而不同点在于,监督学习是已知数据和数据对应的标签,由此得出规律性结论,而强化学习需要通过一次次在环境中的尝试,获取这些数据和标签,然后通过学习,做出得到高分的行为。
常用算法分类
通过价值选行为:
- Q Learning
- Sarsa
- Deep Q Network
直接选行为:
- Policy Gradients
想象环境并从中学习:
- Model based RL
学习方法汇总
是否理解环境
将所有的强化学习方法分为是否理解环境:不理解环境(Model-Free RL)和理解环境(Model-Based RL)
不理解环境的算法包括:Q Learning,Sarsa,Policy Gradients。都是从环境中得到反馈,从而学习。需要等待现实环境给出的反馈,再根据反馈进行下一步的行动。
理解环境的算法包括:比不理解环境的算法多了一个步骤:为现实环境建模。通过建模预判断接下来可能发生的所有情况,然后选择最好的那一种,并根据这种情况来采取下一步的策略。(alpha go)
基于概率/价值
基于概率(Policy-Based RL)和基于价值(Value-Based RL)
基于概率:用感官分析所处的环境,直接输出下一步所采取的各种行为的概率,然后根据概率采取行动。每一种行为都可能被选中,只是可能性不同。算法有:Policy Gradients
基于价值:输出所有行为的价值,选取价值最高者。算法有:Q Learning,Sarsa。
当动作为连续动作时,不能使用基于价值的算法,而应该采用基于概率的算法。
这两种算法结合起来,可以形成一种新的算法:Actor-Critic。即Actor基于概率做出动作,然后Critic负责评估Actor的表现,并指导Actor下一阶段的动作。这种算法在原有的Policy Gradients算法基础上加速了学习过程。
回合/单步更新
回合更新(Monte-Carlo update)和单步更新(Temporal-Difference update)
老师的图画的不错,截来用。
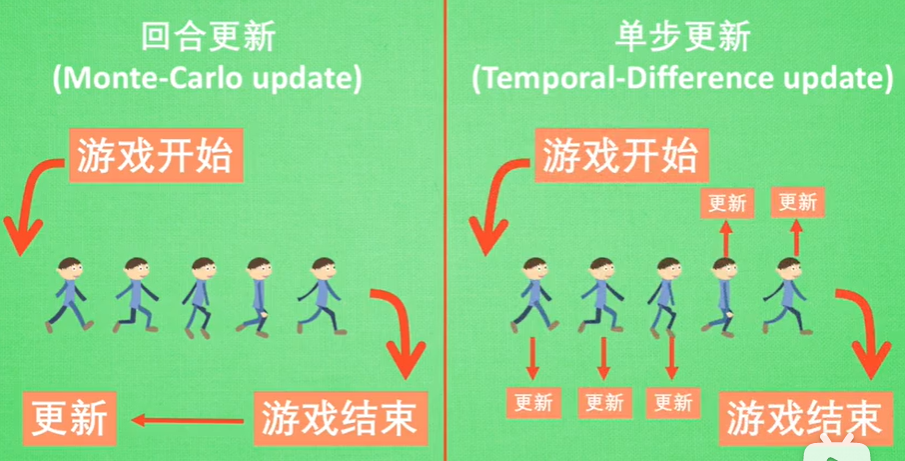
单步更新指在游戏过程中的每一步都在更新。
我的理解是,回合更新是在一轮训练结束之后,更新行为准则,而单步更新就是边训练边更新。
回合更新的算法包括:基础版 Policy Gradients,Monte-Carlo Learning。
单步更新的算法包括:Q Learning,Sarsa,升级版 Policy Gradients。
在线/离线学习
在线学习指先产生一个模型,并在把这个模型放入实际操作中,而不需要在一开始就提供完整的的训练数据集,随着更多的实时数据到达,模型会在操作中不断地更新。
离线学习要求所有的训练数据在模型训练期间必须是可用的。只有训练完成了之后,模型才能被拿来用。简而言之,先训练,再用模型,不训练完就不用模型。
在线学习算法包括:Sarsa
离线学习算法包括:Q Learning,Deep Q Network。