
简介
虽然区块链系统被定义为分布式数据库,但相比较于传统数据库,由于查询语言和查询处理效率的欠缺,在使用中仍然有不便利的情况
传统数据库优点:
- 数据模型
- 存储性能
- 索引
- 查询处理引擎
以fabric系统结构为例(适用于联盟链)
块i中的这些交易来源于某个事件:
- jack给education捐款100
- education给school1发了1000
- school1给tom分发了50
donate和transfer事件都重复记录了多次
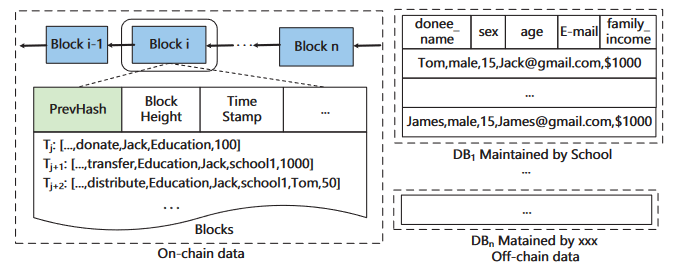
数据同时储存在链上和链下数据库中,交易上链,其他个人信息保存在各个关系型数据库中(例如ChainSQL)
这样的系统存在问题:
- 缺少语义描述:一条交易具有多个属性,针对这些属性进行查询时缺少对应的语义描述;可以加入关系语义来增强查询语句的表达能力
- 操作有限:块中的数据保存在键值对数据库或flat file中(不包含关系结构),针对这种数据的操作有限,不能够对接关系型数据库,也不能进行关系型操作,或是复杂的查询
- 不能有效支持可验证查询:个人用户存储和计算性能有限;很难支持复杂查询的验证
SEBDB实现了:
- 关系语义与区块链的结合:将链上的历史数据组织为元组形式,其中包含数据关系,并实现了类SQL语言来让开发者更便利的进行查询(一条交易数据是一个元组)
- 设计三种操作(create insert select)和三个目录(块目录,表目录和分层目录),提高查询效率
- 重要性:与传统的RDBMS不同,同一表中的数据(即同一类交易)并不是连续储存的,可能分布在不同块中
- 即使是轻量级客户端也可以进行可验证查询
数据模型和结构
数据模型
某一类交易有一个统一的语义描述,基于关系模型
一类交易对应的表有统一的一个模式(table schema),并有对应的表头
交易属性分为两类:
- 应用级属性:由用户定义
- 系统级属性:自动添加到表中
结构
五层结构:
应用层:
- API
- 准入管理:在执行请求之前查询许可证,此时会采用多通道的方法来保护用户的隐私
- 智能合约:支持嵌入类SQL语言,定义一个DApp (去中心化应用),类SQL负责访问数据。
查询处理层:解析、优化和执行类SQL查询
存储层:负责数据存储和索引(创建和维护索引、merkle tree、缓存以及块数据的搜索、扫描和插入)
共识层:可插拔模式,允许用户根据自己的需求来选择不同的共识协议,目前支持kafka和pbft
- 网络层:使用gossip作为底层网络
存储和索引
数据存储
系统同时维护链上和链下数据,其中链下数据由关系型数据库来管理,因此主要重视链上数据管理。可以理解为链下存个人的具体信息,链上存这些用户之间的交易信息。
每类交易都关联到一个用户定义的模式。通常,模式可以作为一个规则表进行存储和维护。系统发送一个特殊的事务来同步节点间的模式。
虽然链上数据的存储单元是块,但是由于属于同一交易类型的数据通常是一起访问的,所以缓存单元是交易类型(即一个表)。
索引方式
针对三种查询场景:
- 给定块id,时间戳或交易id,查找对应块
- 给定某种交易类型,获取对应交易
- 查找对应条件下的交易
三层索引:
块级的B+树索引:按照块id、首条交易id、时间戳作为key进行索引,如果一个块比另一个块先出,那么前者的三个属性一定比后者小,可以满足第一种查询(p1、pn等表示块的位置)
表级Bitmap索引:使用位图索引来记录表的分布。每个位图代表一张表,第i bit代表该块是否存有属于该表的交易。每有一个新表,就新建一个对应的位图,有新块则更新位图
给定10亿个不重复的正int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那10亿个数当中。
解法:遍历40个亿数字,映射到BitMap中,然后对于给出的数,直接判断指定的位上存在不存在即可。
层级索引:基于表的属性建立。
- 第一层:位图或条目,用于记录属性值在块中的分布,其中,对于离散的属性值,一个属性值对应一个位图;连续的属性值,提前建立一个等深度的直方图,每个条目表示一个块中索引键值的范围(bucket表)。其中,直方图是在索引创建时,通过对历史交易进行采样来创建的,直方图的高度可以根据不同的精度进行配置,该直方图相当于是将连续属性转化为离散属性,每个块id对应一个直方图Histogram,其中包含该块中交易的所有连续属性,即可用位图来表示连续属性,即如果出现第i个范围,则将第i位设为1(块中含有300和1000,对应bucket1和3,则把block9的位图第一位和第三位设为1)
- 第二层:B+树,为块内该属性的B+树(pk、pm等)
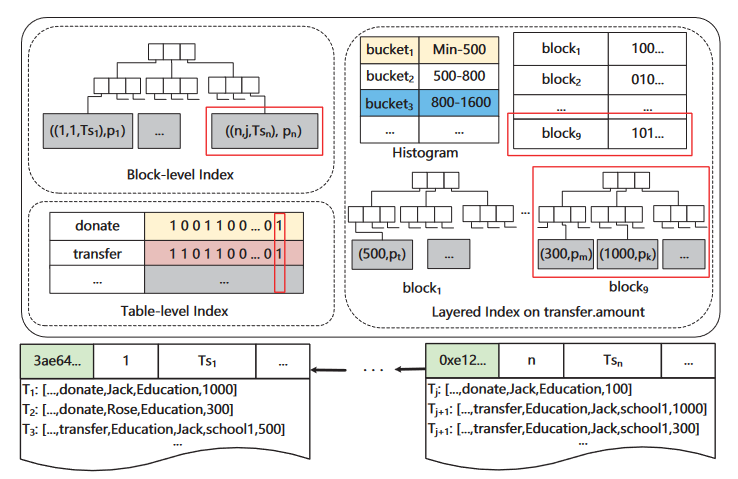
针对范围查询(连续属性):
- 首先在层次索引的第一层索引位图上逐位进行AND操作,如果结果为0,则该条目不含有查询结果,即可过滤掉不满足查询条件的块
- 对于结果为1的块,继续使用层次索引的第二层B+树进行搜索
更新举例
开销分析
查询处理
除了普通的查询操作外,SEBDB定义和实现了一些针对区块链的特殊的操作
示例参考下图
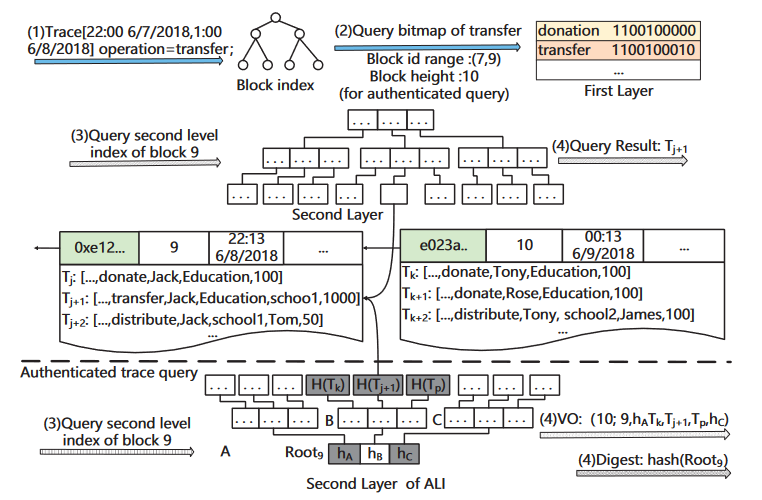
track-trace
一元操作,查找由某方发出的某类交易
如图上半部分1-4步,首先查找符合时间窗口内的块id(7-9号块),获得对应的位图,进行AND操作,如果符合要求则进入B+树进行块内查询
on-chain join
实现交易之间的可追溯性,实现了需要一次扫描的哈希连接,能够与表索引和层级索引结合,进一步提升查询效率,例如追踪杰克捐赠的一笔善款的流向,到某个项目再到特定的受赠者
溯源查询通常使用等连接的方法来查询
查询步骤:
- 扫描所有块,并使用哈希函数h构造表r和表s的划分
on-off join
用于聚合链上和链下数据,例如查询某个捐赠者的个人信息(存在链下的关系型数据库中)
验证查询结果
将层级索引layer中的B+树改为MBT(MHT和B+树的结合)
- SP返回结果时,同时返回VO和块高h
- 用户收到结果后,将查询请求和块高h发送给辅助节点(全节点),辅助节点返回对应的摘要,与VO进行对照
辅助节点可能不可信,用户可以通过向多个辅助节点发送请求的方式来降低风险
